
The Rise and Challenges of Working with LLMs
The year 2023 has undoubtedly been the year in which Large Language Models (LLMs) have experienced a tremendous surge, revolutionizing Natural Language Processing (NLP) across virtually all sectors. LLMs have proven to be superior in any NLP task, enabling increasingly higher accuracies and accelerating developments while facilitating use cases that not long ago were difficult or costly.
Despite this, these types of models tend to “hallucinate” or generate information that may sound plausible but is either untrue or not based on facts. For example, if we ask ChatGPT for what is the winning women’s national team of the 2024 Nations League, it will answer that it does not know (or even hallucinate, answering something incorrectly), when the reality is that it was the Spanish national team. This is because ChatGPT’s knowledge (and that of all LLMs) is limited to that acquired during its training and that which it may receive in the examples provided in the prompt.
Another limitation of LLMs is due to their size and complexity, making the retraining process to improve their performance on specific tasks or to learn from data not observed during their training a challenging and time-consuming process.
Therefore, efficiently employing LLMs in real-world applications can sometimes pose various challenges.
Contextualizing LLM Responses: Retrieval-Augmented Generation
There are different techniques that allow increasing the context with which LLMs work. One of them is fine-tuning [1], which involves updating the internal parameters of the neural network. Another is prompt engineering [2], which focuses on adjusting the model inputs to guide text generation.
But the technique presented in this article, which allows combining the knowledge acquired by the LLM during its learning with external knowledge, is Retrieval-Augmented Generation (RAG). In 2020 [3], researchers from Facebook AI Research (now Meta AI Research) and New York University introduced this new architecture to make LLMs more precise and concrete.
In summary, RAG combines an information retrieval system with large language generative models. Additionally, it makes use of embedding models that encode texts for indexing and subsequent retrieval. Embeddings are pivotal in AI today, adeptly encoding the essence of text, audio, images, and video. By working with textual embeddings, they capture the semantics, making it possible to better understand the language and create more sophisticated NLP applications.
A standard RAG architecture consists of the following modules:
- Information retrieval system: responsible for retrieving information in large datasets, acting as specialized librarians to select the most relevant data according to a user’s query.
- Text generation model: leveraging the LLMs’ ability to understand natural language and their generative nature, they take as input not only the user’s query but also feed it with the information retrieved by the information retrieval system.
- Embedding models: encode texts into numerical vectors that capture both the semantics and the relationship between words and phrases. They allow calculating the similarity between different text fragments and form the basis of the information retrieval systems.
From a functional point of view, the stages carried out in a RAG process, illustrated in the following diagram, are as follows:
- A user poses a question using everyday language. Initially, this inquiry isn’t sent straight to the large language model (LLM) but is instead processed through a search within a dedicated knowledge base that the system can access. This knowledge base is designed to store and provide the necessary information for query resolution.
- To facilitate the search, the system calculates the embedding for the user’s question. The knowledge base content has been pre-processed, with each document converted into an embedding for efficient indexing. By comparing the question embedding with those of the knowledge base documents, the system can identify and retrieve the documents most relevant to fulfilling the user’s informational needs.
- Following retrieval, the question alongside the selected text fragment(s) (relevant documents) from the knowledge base is forwarded to the LLM. This combined input allows the LLM to generate an informed response, leveraging both the original user query and the contextual information gleaned from the knowledge base documents.
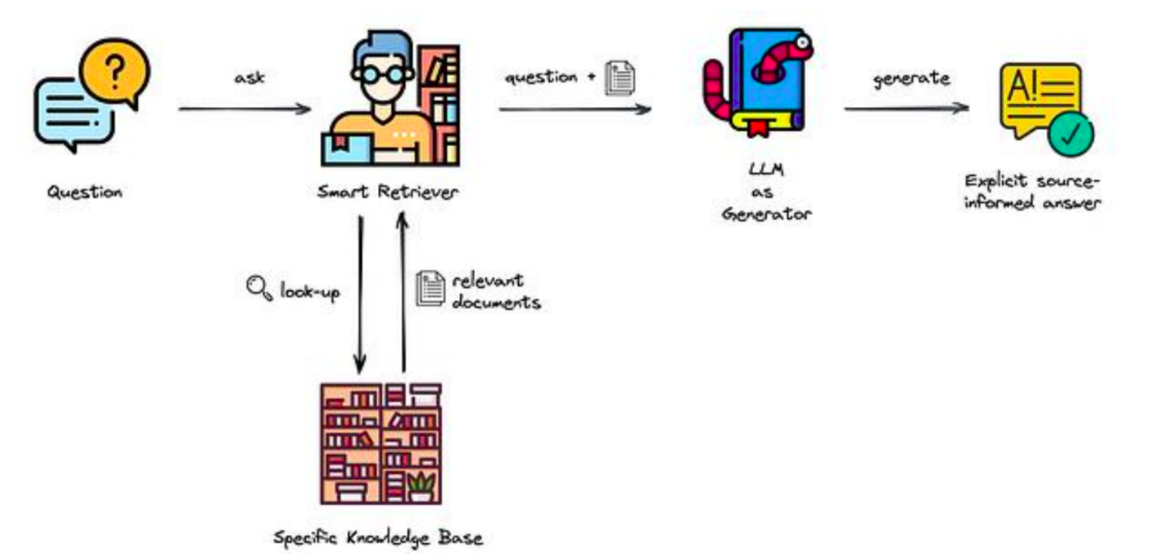
Source: Leveraging LLMs on your domain-specific knowledge base [3]
By incorporating an external knowledge source through document retrieval and utilizing a generative language model, RAG effectively bridges the gap between retrieval-based and generative models. This results in more informed and accurate responses for specific tasks compared to traditional queries to a LLM.
Conclusion: Advantages and Some Disadvantages of Using RAG
There are multiple advantages that RAG offers. Highlighting some of them:
- It reduces hallucinations: By grounding responses in factual data, RAG reduces the chances of generating incorrect or fabricated information.
- Updated LLM knowledge: Without the need for fine-tuning, updating the information contained in the knowledge base is sufficient for the model to access new and verified information.
- Ideal for applications where there is a multitude of available but unstructured or unlabeled information.
- Improves LLM precision when working with documents it has never seen before and in highly specific domains. This includes private or internal company documentation, for example.
However, it’s also important to identify some disadvantages:
- Effectiveness of the information retrieval engine: RAG’s effectiveness heavily relies on the quality of the information retrieval engine. This often involves preprocessing documents, appropriate chunking, selecting the right embedding model, or choosing suitable text similarity metrics.
- Context length: LLMs have a context size limited to a certain number of tokens, so it will be a limitation of the system when working with knowledge sources where information is spread across large text fragments.
- Dependency on knowledge base data: As with any process, it’s crucial that data is available and of quality. The relevance of responses will largely depend on this point.
In 2023, the integration of Large Language Models (LLMs) with Retrieval-Augmented Generation (RAG) significantly advanced Natural Language Processing by addressing LLMs’ limitations such as fact “hallucination” and knowledge updating challenges. RAG combines LLMs’ generative abilities with factual data retrieval, enhancing accuracy and reducing misinformation without extensive retraining. However, its effectiveness relies on the quality of the information retrieval system and the availability of high-quality data.
[1] Getting started with LLM fine-tuning, https://learn.microsoft.com/en-us/ai/playbook/technology-guidance/generative-ai/working-with-llms/fine-tuning
[2] Prompting Techniques, https://www.promptingguide.ai/techniques
[3] Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models, https://ai.meta.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/
[4] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, https://arxiv.org/pdf/2005.11401.pdf
[5] Leveraging LLMs on your domain-specific knowledge base, https://www.ml6.eu/blogpost/leveraging-llms-on-your-domain-specific-knowledge-base
Author: Carlos Rodríguez Abellán, Official Expert of GENAIA
Co-author: Yeison Villamil, representative of Stratio as an Official Expert of GENAIA